
When Cloudflare Sneezed Yesterday, Half the Internet Caught a Cold – The November 18, 2025 Outage
When Cloudflare Sneezed Yesterday, Half the Internet Caught a Cold
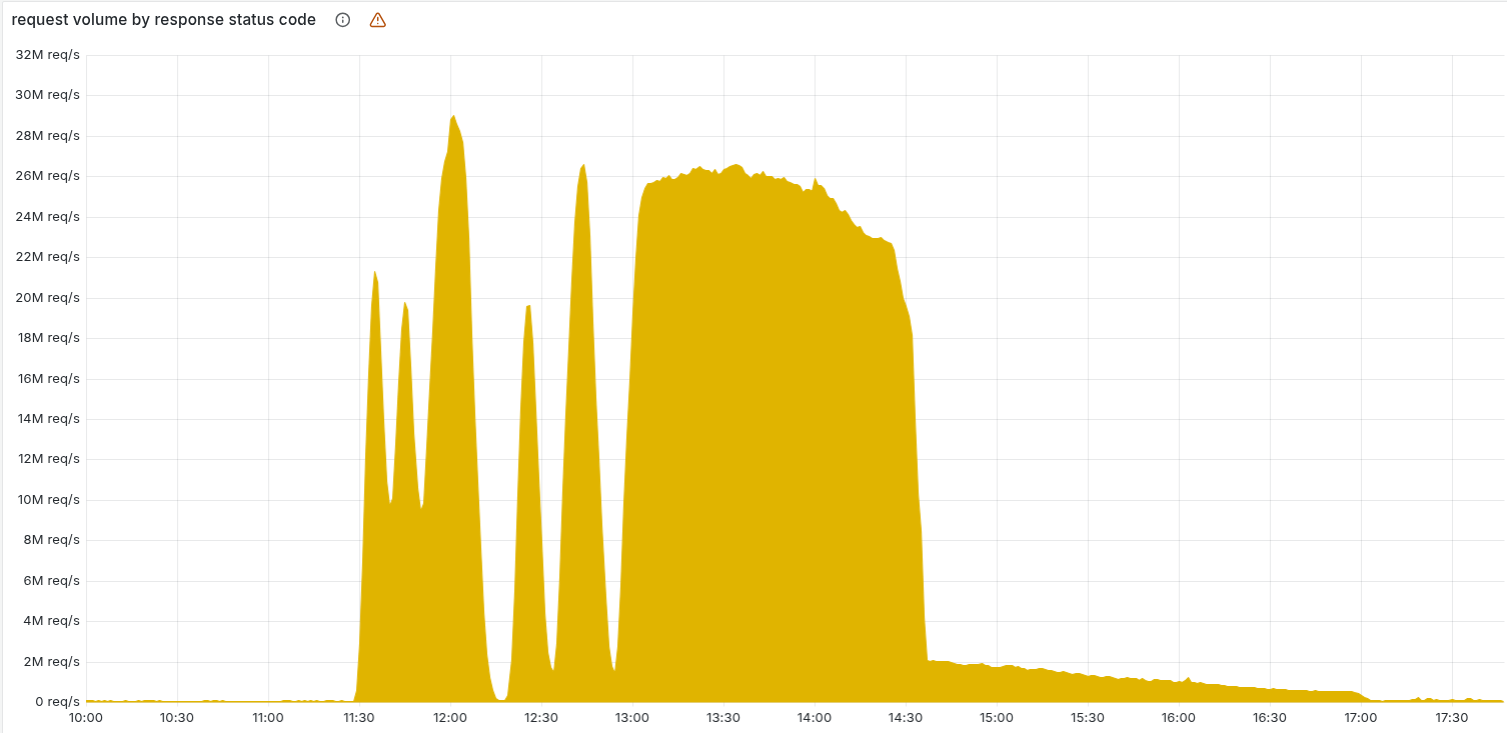
Yesterday morning (November 18, 2025), around 11:20 UTC, a good chunk of the internet decided to take an unplanned coffee break. If you tried to load X (formerly Twitter), ask ChatGPT for life advice, queue up Spotify, or even check Downdetector to see if everyone else was down… you probably saw a lovely Cloudflare 5xx error staring back at you.
Yes, Cloudflare – the orange-cloud company that sits in front of ~20% of the web – had a bad day. And because we all love putting our eggs in the same brightly-coloured basket, the ripple effect was glorious.
What Actually Happened? (The Technical Bit)
Cloudflare’s CTO summed it up nicely on X: a latent bug in their Bot Management system woke up after a totally routine configuration change.
Here’s the play-by-play (simplified, because I’m not trying to write their postmortem for them):
- Cloudflare made a small permission change to one of their internal database queries (the kind of thing you do 47 times a day in prod and nobody notices).
- That change caused the query response to suddenly include extra metadata – basically doubling the number of rows returned.
- Those rows feed into an automatically generated “feature files” used by the Bot Management / Bot Fight Mode module.
- One of those feature files ballooned in size (think going from a tidy CSV to War and Peace).
- The oversized file got pushed out to every edge node in Cloudflare’s global network.
- The Bot module, which has strict memory limits to stop rogue configs eating all the RAM, saw the massive file → panicked → crashed.
- Because the Bot module is loaded into the core proxy path for a huge number of requests, any traffic that touched it started returning 500/502/504 errors.
- Bonus chaos: Cloudflare Dashboard, API, Workers KV, Cloudflare Access/WARP – anything that went through the proxy – also fell over.
Result? Widespread 5xx errors for ~3 hours until they rolled back the change, purged the bad files, and restarted the affected services.
Moral of the story: even “immutable” config files can bite you if you accidentally make them mutable… and huge.
(And yes, this is why we have canary deployments, size limits, schema validation on config generation, etc. We all nod sagely now.)
Who Got Hit? (The Casualty List)
If it was behind Cloudflare (CDN, DDoS protection, Zero Trust, etc.), it probably broke. Some highlights:
- X (Twitter) – Elon probably sent a few strongly-worded memos.
- ChatGPT / OpenAI – AI went on strike. Millions suddenly had to think for themselves. Terrifying.
- Spotify – Playlists stopped. People were forced to listen to office chatter.
- Discord – Gamers couldn’t complain in voice chat.
- Shopify stores – Black Friday prep? More like Black Screen Tuesday.
- League of Legends / Riot Games – Ranked queues paused. Toxicity levels dropped 0.0001%.
- Grindr, Perplexity, Claude (Anthropic), Crunchyroll, DoorDash – the list goes on.
- Even Downdetector went down – the ultimate irony. “Is the internet down?” “We can’t tell you… because we’re down too.”
Cloudflare stock dipped ~3% during the day, but honestly that’s pretty mild for “we accidentally unplugged a fifth of the web”.
The Humour in the Chaos
My favourite tweet from the incident:
“Cloudflare is down, so I can’t check if Cloudflare is down because DownDetector is also behind Cloudflare.”
— every SRE yesterday
Or the classic:
“Single pane of glass? More like single point of failure.”
We’ve all been there. You push what you think is a harmless change, grep shows nothing suspicious, monitoring is green… and suddenly the internet is on fire.
Lessons for Us Mere Mortals (DevOps Takeaways)
- Validate generated configs – add size checks, schema checks, diff-on-deploy.
- Canary everything – even internal config rolls. Push to 1% of nodes first.
- Circuit breakers & fallbacks – if your bot score service dies, maybe just let the traffic through instead of 500ing everything?
- Multi-CDN / Multi-provider is looking pretty attractive right now. (Fastly and Akamai were having a great sales day yesterday.)
- Chaos engineering – go break things on purpose in staging so prod doesn’t get the honour.
- Have a “kill switch” that bypasses optional features under load.
Final Thought
Outages like this are a humbling reminder that no matter how many 9s you promise, the internet is still held together with duct tape, caffeine, and the occasional lava lamp (yes, Cloudflare really uses lava lamps for entropy).
Stay safe out there, keep your changes small, and maybe keep a book nearby in case ChatGPT takes another nap.
Until next time – may your deploys be boring and your on-call quiet.
P.S. Cloudflare promised a full postmortem on their blog soon. I’ll update this post when it drops (assuming their blog isn’t… you know). 😏
UPDATE : https://blog.cloudflare.com/18-november-2025-outage/
// RELATED_ARCHIVES

> Dec 2025 · 7 min read
React's React2Shell Hack: When Your UI Library Gets a Backdoor
A critical RCE bug (CVE-2025-55182) in React Server Components let hackers shell into millions of servers. Patch now, or your app's serving more than just JSX.
> Dec 2025 · 5 min read
React's RCE Wake-Up Call - Patch Before Hackers Say 'Hello World'
CVE-2025-55182 hits React Server Components hard with unauthenticated RCE. A quick dive into the deserialization drama, who's affected, and how to fix it without pulling your hair out.

> Dec 2025 · 5 min read
AWS's New AI Coders: Will They Finally Fix My Deployments?
AWS just dropped AI agents that can write, debug, and deploy code like a caffeinated intern. DevOps pros rejoice (or panic)